 Tira Sundara
Tira Sundara


Recently, my team and I managed to migrate millions of our users’ data with no downtime required. In this post, I’m going to share why we did it, how we did it, and what we’ve learned from this.
Background – Why Do We Need To Migrate, anyway?
Initially, our organization relies on a monolithic database system (MongoDB) to manage a wide range of functions, including user identification, authentication, authorization, content-checking, payment, etc. However, as the demands on our system have grown, it has become clear that this single, all-encompassing database hinders our ability to efficiently and effectively manage and expand our services.
To achieve separation of concern and improve efficiency, our organization has decided to undertake a database migration project. However, through this migration, we aim to create dedicated databases for specific functions, such as authentication & authorization, two-factor authentication, and passwordless login systems.
In short:
We need a dedicated database to store users’ account data – for authentication and/or authorization purposes.
Setup The Goals
Before the migration, our architecture looked like this:
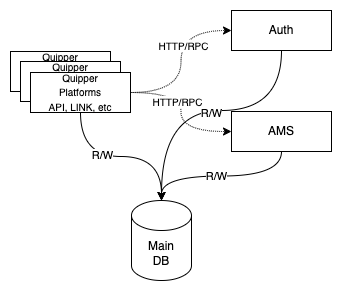
It has changed to this:
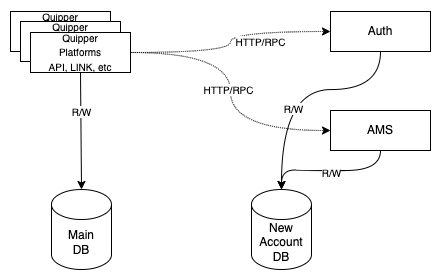
Please note, in this post, we refer to Main DB as the old database, and the New Account DB as the new database.
Research & Preparation
“If I only had an hour to chop down a tree, I would have spent the first 45 minutes sharpening my axe.” – Abraham Lincoln
This is the most important step. Before we start the migration, we have to spend some time preparing and doing some research to make the migration run as expected with minimum (or even zero) impact on the current live production environment.
In this step, we identify the entities to be migrated, calculate the size, then analyze what kind of database we need for the new Account DB, and finally, we define the migration steps.
Identify Entities To Migrate
After we analyzed the current implementation of the auth service, we found out that we have to migrate at least five entities (called collections in MongoDB, or tables in SQL databases). Those collections are: users, access_tokens, teams, authentications, and clients.
In total, there will be around 32 million documents to be migrated from our Main DB (old DB) to the new Account DB – it is about 25 GiB in size.
What Kind of Database do We Need?
As I have mentioned earlier, our Main DB is running on a MongoDB server, and it’s running very well. Then, what kind of database that we are going to use in this separation/migration project?
This one might be debatable, but after going through several discussions, we go with MongoDB (again? Yes), here are our considerations:
- Easy to scale – High Availability
- We don’t need a strong transactions mechanism here
- No requirements for joining many different types of data
- MongoDB also provides the Time To Live Index – We will be able to auto-delete expired
access_tokenswithout adding any additional service like a Job-scheduler or something.
Migration Strategy
Can we do this migration in one go and that’s all?
The answer is NO. Many services currently read/write from and to our migratable collections in the Main DB. So we can’t just migrate those collections to the new DB and switch to read/write from/to the new DB.
I mean, in the simplest terms yes, the step is just migrating all of the data from the old DB to the new one, and then we switch the services to read/write to the new DB. But unfortunately, it is not that straightforward. Since we are working with a monolith database that receives a lot of read and/or write requests from many services. Instead, we have to split the overall migration process into several granular steps or phases.
How to actually migrate those data? So, let’s split the migration process into several actionable phases:
- “Double Write” Any New Changes
- Copy data from the Main DB (old DB) to the new Account DB – Do we need downtime?
- Make sure the data between Main DB and the new Account DB is always synch
- After we’ve confident enough, we can start reading from the new Account DB
- Then, finally, we can stop writing related data to the Main DB
Migration Implementation
“Double Write” Any New Changes – a.k.a Replication
At this point, we need to find a mechanism for synchronizing any new changes in the Main DB (old DB) to the new Account DB, so the changes that happened in Main DB will be mirrored in the new Account DB. How? Here are several solutions that we can follow:
It’s important to note that there are other options available, but for the purpose of this post, we will be focusing specifically on the comparison of two options, and explaining why we chose one over the other.
Synchronization via API end-points
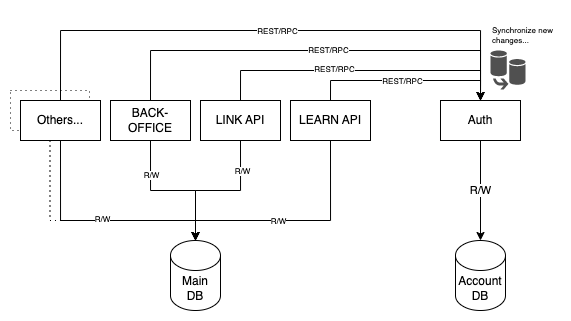
So, here is the flow:
- The
authservice establishes connections to the new Account DB - The
authservice reserves API end-points for synchronizing new changes tousers,access_tokens,teams,clients, andauthenticationscollections in the newAccount DB - Quipper Platforms such as:
LEARN API,LINK API,Back-Office, and other services will act as the clients of the API end-points defined byauthservice - On every change that happens to those collections in Main DB, Quipper Platforms will make an HTTP (or RPC) call to
authservice to synchronize those changes - The
authservice will receive each request and process it (basically, CRUD to the new Account DB)
We think this solution is quite simple, but there are several drawbacks:
- Looks like this solution is not reliable enough, it will be prone to network failure
- This will also give a huge additional load to the
authservice - This “mirroring” process is not
authservice’s responsibility anyway – so we don’t want to compromise to risk ourauthservice being down for handling requests that are not even its responsibility - And, we have to make changes in many places:
API Learn,Educator API,Back-Office, etc
So, we didn’t choose this option.
Change Data Capture: The MongoDB Changestreams
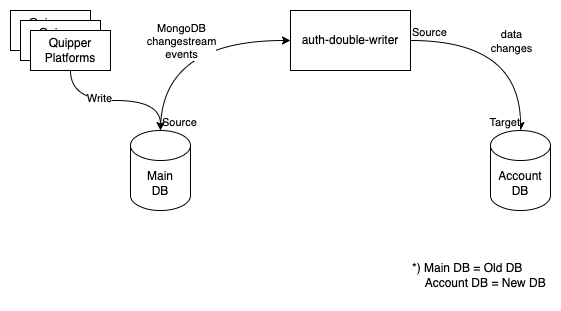
After careful consideration, we chose this option. In this option, we fully utilize the feature of MongoDB called Change Streams. Our Main DB has the ability to stream every event/change that happens inside, and at the other end, our app will be able to watch/listen to every streamed event/change to process it further.
We also introduced a new service called auth-double-writer. This service is written in Go. The responsibility of this service is to replicate any changes by watching (or listening) to any changes that happen to the collections in the Main DB and then write those changes to the new Account DB.
MongoDB Change Streams
Change Streams allows applications to access real-time data changes without the complexity and risk of tailing the oplog. Applications can use change streams to subscribe to all data changes on a single collection, a database, or an entire deployment, and immediately react to them.
- Change Streams is available for replica sets and sharded clusters
- Watch a Collection, Database, or Deployment
- Modify Change Stream Output –
$addFields,$match,$project, etc - MongoDB Changestream is resumable –
resumeAfter,startAfter - Use Cases:
- Extract, Transform, and Load (ETL) services
- Cross-platform synchronization
- Collaboration functionality
- Notification services
- Change Events (v6.0):
createcreateIndexesdeletedropdropDatabasedropIndexesinsertinvalidatemodifyrenamereplaceshardCollectionupdate
Copy Data from Old DB to the New DB
We have two options on how we will execute the actual migration step. The first one is with downtime required, and the second one is without downtime.
With Downtime Here are the steps:
- Turn off
auth-double-writerservice - Turn off Quipper services (downtime)
- Run the job to copy the data from Main DB to the New Account DB
- Turn back on
auth-double-writerservice - Turn back on Quipper services
Without Downtime
It is possible to run the migration without downtime since our auth-double-writer service has a “pause and resume” capability (thanks to MongoDB Changestream’s resume token). Here are the steps:
- Turn off
auth-double-writerservice - Run the job to copy the data from Main DB to the New Account DB
- Turn back on
auth-double-writerservice
We have determined that the latter option is preferable, the database migration with no downtime is the best course of action as it maintains continuity of service for our users and minimizes potential disruption.
Execute The Migration With Zero-Downtime
We finally managed to execute the migration with zero downtime (cheers!). The question is how did we do that? Let me explain to you.
The main reason why we managed to execute the migration with zero downtime is that MongoDB Changestream is resumable. So, the auth-double-writer utilizes this capability very well.
We’ve designed our auth-double-writer with “paused” capability, and resume from the point it left. So it will be able to listen to the events stream continually as if there is no disruption.
This is what actually happened:
- When we turned off the
auth-double-writerservice, theauth-double-writerstores the last Changestream token that has been processed to some datastore – we can use some persistent datastore to store the Changestream tokens here - Then, we executed our main task: copy the data from the Main DB to the new Account DB
- We’ve carefully tested this step
- We’ve run the job several times before (for testing purposes)
- Based on the test result, we’ve calculated that on average this job will take 30 minutes to run. This is a safe number since our MongoDB Oplog can hold the Changestream tokens for one hour long
- We turned back on the
auth-double-writerservice. This service will pick up the Changestream token from the data store, so it will continue to listen from the point when it was being turned off - We checked the data integrity and compare the size and the number of records between the Main DB and the new Account DB. Thankfully, all is good
- Now we’ve fully replicated data from the Main DB to the new Account DB and kept them synced
Conclusion
As we have seen throughout this article, database migration is a complex process that requires careful planning and execution. However, the benefits of separating concerns, improving performance, and ensuring continuity of service through zero-downtime migration make it worth the effort. With this migration, our organization will be better equipped to handle future demands, and we will continue to deliver the best possible service to our users.
Thank you for your time in reading this post. See you later.
Originally published at https://tirasundara.hashnode.dev.